[WIP]AI编译技术调研
总结一些AI编译相关的知识
内容包括我对TVM, ansor, MLIR的一些学习与浅显理解
TVM-2018
TVM,一个端到端的深度学习编译器,从onnx或者pytorch等格式的模型,经过计算图级优化和算子级优化后,生成可部署到各个硬件平台上的二进制程序
计算图级优化
传说中的编译模型,通过常量折叠、算子融合操作优化计算图在执行时的耗时,除此之外还可以提前relayout一些数据,使其在执行时对硬件访存/计算特性更加友好
算子融合
论文中将算子分成了四种1. 一对一映射,2. 规约,3. 复杂的,但是输出可以融合,4. 不能融合的。
作者提前定义了一些融合规则来进行算子融合。算子融合的好处,减少对中间结果的重复访问/冗余的写回与读取操作,对于GPU和NPU这种需要kernel launch的加速器来说,还可以降低kernel launch的开销
算子级优化与代码生成
TVM提供了tensor expression(te)和支持各种硬件的一系列调度原语(schedule primitives),调度是在不改变原程序逻辑定义的前提下,在原程序基础上进行一系列的代码变换,比如tile,向量化(使用simd),张量化(使用类mma指令)等。
基础使用方法:使用te描述算子的计算定义,在此定义之上应用一系列的调度原语,
至于对某个算子应该使用哪些调度原语是需要程序员根据hpc的一些知识提前写好的,以模板的形式(topi)存在于tvm的代码中(在引入ansor,也就是autoschedule模块前是这样的),对外提供api。
关于调度原语的具体使用有两种方式,一种是写死,比如说,对于这个算子就该在这个循环进行一次tile,tilesize就该是128,就该这层循环上向量化,就该在另一层循环上并行化,不需要搜索的过程,可以直接build,还有一种是,我知道需要tile,但是在哪个维度tile是可调节的(knob)或者说是需要搜索的,tilesize也不是固定的,也是可调节的,这种情况下需要使用autotvm定义搜索空间,经过搜索后返回最优的函数。
下面这个链接里有具体使用例子,还带上了ansor(auto_schedule)
如何使用te搭配写死的调度原语生成接近手写性能的GEMM论文:
对于用来减少搜索耗时的ML-Based Cost Model就不深入了解了。Distributed Device Pool and RPC也掠过。
Ansor
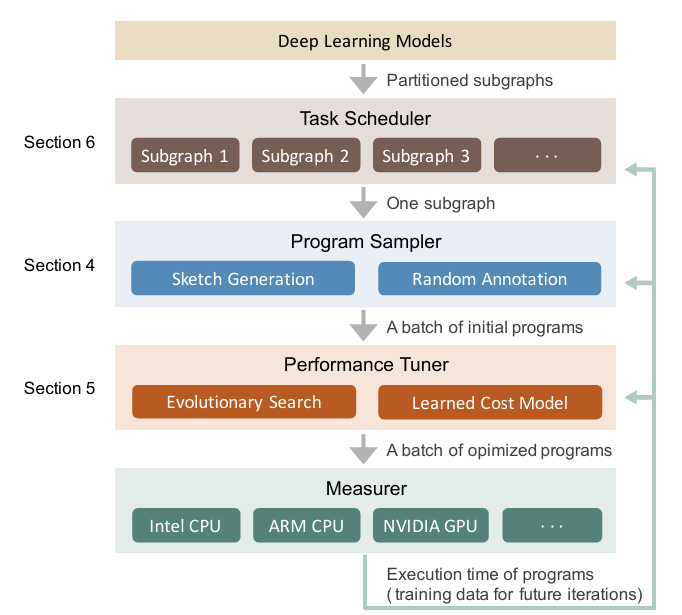
Ansor是一个针对深度学习程序的张量程序生成框架,使用从Relay中引入的算子融合算法将一个ONNX或其他格式的深度学习模型转换成多个子图,针对每一个子图自动生成搜索空间(TVM原有搜索空间是基于手写模板定义的),然后采样选择最优的程序。论文贡献:
- 提出了一种针对计算图生成巨大启发式张量程序搜索空间的方法。
- 使用基于cost model的进化搜索策略精细调优张量程序。
- 提出一种基于梯度下降的调度算法,智能的给整个DNN的多个子图做一个优先级排序,分配相应的搜索时间片。
- 对Ansor系统做了全面的评估,上面提到的技术使Ansor效果拔群。
2的主要目的是为了在尽量不错过最优实现的前提下减少搜索耗时,3的目的是为了在可接受搜索耗时一定的情况下,将更多搜索耗时花在比较重要的子图上。4没啥好说的就是做了一些测试展示优越性。所以下面将主要关注ansor是怎么自动生成搜索空间,并生成完整程序的。
现有张量编译器在搜索空间定义上的缺点
一类是以TVM为代表的基于手写模板定义搜索空间,缺点是手写很难枚举所有可搜索情况,导致搜索空间不够大,不能包含最优实现,而且手写模板需要大量的手工工作,不同的算子在不同的硬件上需要不同的模板。还有一类是基于顺序结构的搜索,一步一步的构造完整的程序,编译器依赖构造过程中不完整的程序来决定下一步应该怎么变换。缺点是剪枝策略较为激进,可能把最优实现剪掉了,而且依赖不完整程序做出的决策并不可靠。
Ansor的分层方法
Ansor将搜索空间分成了高级结构(sketch)和低级细节(annotation, e.g. tile size, parallel, unroll annotations)。Ansor为计算图自动的构造搜索空间,省去了手写模板的工作。一个完整的程序需要先枚举可能的高级sketch,然后针对sketch确定annotations。
Sketch的生成
对于一个输入子图,ansor首先对他进行拓扑排序,对于这个节点序列,递归的做一些检查并应用一些规则来进行变换。对于计算密集有很多重用数据的计算节点,ansor构造了一个基础的固定的tile结构(这个多层tile结构可以通过将某些循环的长度设为1来实现交换循环顺序和减少tile层数的效果,但是仍然不够灵活)。简单的element-wise的节点可以安全的内联(???没懂,可能是指嵌到其它节点的tile结构里?)。在sketch生成的过程中可以额外插入一些cache node和layout transform节点(不知道这个节点能不能嵌到其它节点的tile结构里,如果不能的话,对矩阵乘法来说就只能在最外面把整个矩阵提前relayout了)。
论文里定义了一个状态(S, i),S是对输入DAG生成的部分Sketch,i是当前工作节点,将DAG按照拓扑排序后,从最后一个结点开始尝试应用各种规则(论文里提到6种规则),在满足相应的条件后,可对当前Sketch做相应变换,进入下一个状态(一条规则可能有多个后继状态,广度优先搜索,用队列保存多个状态等待处理),依次处理完所有节点后进入终止状态,此时一个完整的Sketch就生成好了,队列清空时Sketch空间生成完毕。
论文里提到了6条CPU上的派生规则:
- Skip,如果此节点操作不可内联,就直接跳过这个节点。
- Always Inline,如果这个节点操作可以内联,就尝试嵌到下一个节点的tile结构里。
- Multi-level Tiling,如果当前节点有数据重用,就对代码做多级tile的变换,论文里将张量计算的维度分成了两类,一类是空间维度S,一类是规约维度R,CPU上使用固定的SSRSRS的结构,以矩阵乘法为例,这个变换会将原始的3重循环tile成10重循环,作者认为这个tile结构对计算密集型算子(matmul,conv)够用了。虽然可以将某层循环的长度设为1消除循环来实现改变tile结构循环顺序的目的,但是还是有一定局限性的,假如10重循环的长度都不为1,就不能交换循环顺序,是一个固定的tile结构。
- Multi-level Tiling with Fusion,如果当前节点有数据重用且有一个可融合的消费节点,就对当前节点做多级tile的变换并将后继结点融合进tile结构里。
- Add Cache Stage,如果当前节点有数据重用且没有可融合的消费节点,就对当前节点做多级tile的变换,并将输出写到一个Cache Block里,而不是直接写回内存。
- Reduction Factorization,如果当前节点在规约的维度上有更多并行的机会,就使用rfactor将规约维度分解到空间维度去并行(暂时没仔细了解,可能是和splitK类似的操作?)。
上面这些规则的条件是否满足是通过分析子图计算定义中张量的读写模式得出的,论文里没有展开,可能和编译里数据流分析类似?
举一个例子:矩阵乘法后跟一个Relu激活函数,拓扑排序后是(A,B,C,D)

经过如下流程(所以inline到底是个什么操作,这里将relu判定为不可inline的,直接跳过了):

得到如下sketch:

对于GPU,ansor将多级tile结构设定为SSSRRSRS。最外面三层空间维度依次被绑定到线程块(BlockIdx),线程束(Warp,论文里叫虚拟线程),线程(threadIdx)上。除此之外还增加了利用shared memory的规则和跨线程规约的规则。
低级annotation
sketch只确定了高级tile结构,是不完整的程序,还需要确定在哪层循环并行、向量化,循环展开次数,tilesize等细节才行。ansor随机设定这些细节然后进化搜索,搜出最好的组合。
评估结果
论文在三个层面评估了程序的性能:单算子,子图,整个神经网络模型。作者的结论是,截止到他做实验,ansor的效果在各个平台上好于pytorch(后端使用厂商提供的加速库),halide,autotvm,flextensor。
MLIR
https://mlir.llvm.org/
还是让我们去A几道力扣吧家人们。
真·浅显理解
现有LLVM IR的描述能力有限,不能完美的表示各个高级语言的特性,导致大家都针对自己的特性搞了一套自己的IR,然后从这个IR lower到LLVM IR。MLIR的设计初衷是解决上述问题,提供一个通用的基础设施来减少工程量,使得不同硬件上的不同DSL编译器开发更加方便。
MLIR 使定义和引入新的抽象级别变得非常方便,并提供“开箱即用”的基础设施来解决常见的编译器工程问题。MLIR 通过 (1) 标准化基于静态单赋值 (SSA) 的 IR 数据结构,(2) 提供用于定义 IR 方言的声明性系统,以及 (3) 提供广泛的通用基础设施(包括文档、解析和打印逻辑、位置跟踪、多线程编译支持、传递管理等)来实现这一点。
MLIR 设计原则
- 极少的内置,高度的可定制化。系统提供了最少的通用的基础设施,大部分的IR都是用户可定制的。可以将计算图、AST、控制流图表达成IR。
- SSA和regions。使用SSA格式表示IR。现有IR使用扁平的线性的CFG,但为了表示更高级别的抽象,还需要嵌套区域(nested region)。这个更高级别的抽象加快了编译过程,有利于提取程序的SIMD并行性。为了支持异构编译,MLIR需要支持结构化控制流,并发结构,闭包等的表达。
- 渐进的将程序从高级表示降级到低级表示。以前存在的编译器也有多级IR,但是层级是固定的。对程序(不管是AST还是数据流图/控制流图)的遍历、分析与变换被称为pass。pass大概有4类,优化变换,赋能变换(enabling transformations),降级(lowering)(4)清理(cleanup)。
- 维护高级语义。系统需要保留分析或优化性能所需的更高级别的语义和计算结构。例如,系统应该在变换过程中保留像循环结构这种控制流信息。例如,这将使自定义加速器的编译器能够重用系统定义的一些更高级别的结构和抽象,以及特定于加速器的原语标量/向量指令。
- IR validation。开摆。
- Declarative rewrite patterns。开摆。
IR设计详情
基于SSA的IR数据结构。
- Operations。MLIR中语义的基本单元是Op。在MLIR中指令、函数、module都被建模成Op。MLIR中没有固定的Op集合,它允许或者说鼓励用户定义拓展(编译器pass保守的对待未知Op)。Op是MLIR中的主要实体,Op包含一系列的regions,regions包含一系列的blcok,block包含一系列的Op,这是一个递归的结构。每个Op都有独一无二的Opcode,是用于标识其方言和操作的字符串。Op以SSA的形式获取0个或多个输入,产生0个或多个输出。所有值都有类型。除了Opcode、操作数、结果外,Op还有属性(Attributes),Regions,Block Arguments,Location information。在可视化的IR表示中,Op是用引号包起来的字符串,value是%开头的标识符,:指定一个数据包中数据的个数,#代表特定值。
- Attributes属性。属性是像常量、字符串这些的结构化的编译期静态信息。属性有类型,每一个Op都有一个字典存属性,key是字符串形式的属性名,value是属性值。在可视化的IR表示中,属性在Op和类型之间,并用花括号括起来。()->(0)代表了一个放射函数,这个函数产生一个常量0。和Op一样,MLIR中的属性也不是固定的一个集合,也是可以自定义扩展的,可以引用外部数据结构。
- Location information位置信息。MLIR为定位信息提供了一个紧凑的表达方式,并且MLIR希望这个信息能够在整个系统中传播使用。它可以用来保留源程序堆栈跟踪,产生可以生成调试信息的Op。位置信息也是可扩展的,允许编译器引用现有的位置跟踪系统、高级 AST 节点、LLVM 样式的文件行列地址、DWARF 调试信息或高质量实现所需的任何其他信息。
- Regions和Blocks。一个Op可能有一系列的regions。regions为嵌套结构提供了一个机制:region包含block,block包含Op,Op包含region,这就递归起来了。和属性一样,region的语义取决于它从属的Op,region内的Block形成控制流图。每个region的body都是一系列的block,每一个block都有一个终止Op,终止Op可能有后继block,终止Op后控制流转交给后继block。不同控制结构有不同的终止Op。
MLIR中没有phi节点了,它使用SSA的函数形式,终止Op将值传进后继block的block arguements。每一个block都有一系列有类型的block arguements。终止Op的语义定义了应该给后继块传什么参。对于一个region内的入口block,它的参数由region的封闭Op的语义定义 - Value dominance and visibility值作用域和可见性。使用前先定义,作用域的概念和以往的认知没什么不同,就不仔细了解了。
- Symbols and symbol tables符号和符号表。符号表从属于Op,表里是字符串形式的符号,其含义由Op定义。
- Dialects方言。MLIR使用方言实现可拓展性,方言在一个唯一的命名空间里提供一组Op、属性和类型。方言可以包含硬件向量上的一些Op和类型,也可以包含代数向量的Op和类型。不同的方言中间是否使用相同的向量类型以及这种类型属于哪里,是留给MLIR用户的设计决策。
- Type system类型系统。MLIR中的所有value都有类型,可在Op产生值时指定类型也可在block arguments中指定。类型为IR提供编译期的语义。MLIR中的类型系统是用户可拓展的。
- Standard types标准类型。此外,MLIR提供了一组标准化的常用类型,包括任意精度整数、标准浮点类型和简单的通用容器——元组、多维向量和张量。这些类型只是对方言作者有用的便利,但并不需要使用。
- Functions and module函数和模块。与传统的IR类似,MLIR通常被组织为为函数和模块。但在MLIR中他们也可以是一个Op。
IR infra
除了IR本身,MLIR还提供了定义IR元素的基础设施,如方言、操作、模式重写、验证和可重用pass。
- MLIR使用基于TableGen的规范定义Op(ODS)。相当于提供了一个DSL,用户使用这个DSL描述自定义Op,这个定于最终会被翻译成c++代码,与系统的其余部分互操作。
- 声明式重写。MLIR提供了一个图重写框架,并辅以声明性重写规则(DRR)系统,使表达模式变得简单。DRR也是一种DSL,也会被转换成c++代码。。。。
- Pass manager。MLIR的pass可以在不同粒度的IR上使用。。。。
- Round-trippable textual IR form。IR和Op在MLIR中都有文本表达形式。MLIR允许自定义IR的打印和解析。。。
- Documentation。ODS描述的东西还会生成文档。。。。
- Verifiers。开摆。。。。
MLIR的一些应用
工业界学术界对MLIR是一片好评,并且有很多实际应用的例子。
- TensorFlow graphs。这是一个使用MLIR来支持机器学习框架开发的例子,机器学习框架的中间表示通常是有动态执行语义的数据流图形式。tf的中间表示是一个高级的数据流计算图,图上节点是各个硬件设备上的计算。MLIR在Tensorflow中用于建模中间表示并执行一些变换:比如从简单的代数优化(???)到将图重定向至数据中心加速器上的并行执行,从 降级到可部署到移动设备上的代码 到 生成使用类似XLA这种工具的高效代码。
- 多面体代码生成。MLIR的最初动机之一是探索加速器的多面体代码生成。仿射方言是一种简化的多面体表示,旨在实现渐进式降级。(有点抽象,开摆。。。)
- FortranIR。在MLIR出现之前,fortran自己定义了一套在LLVM IR之上的IR,用来对Fortran代码在IR级做一些优化变换。有了MLIR之后,可以使用MLIR提供的一些基建来自定义Op,自定义优化变换pass。这些高级优化——高级循环优化、数组复制消除、调用专门化、去虚拟化——仅使用LLVM很难实现。
- 领域特定编译器。MLIR提供的一些基建大大简化了开发领域特定编译器的工作流,效果很好,点个赞。
Consequences of the MLIR Design
_ (:3 」∠)_
最后
论文最后认为MLIR在ML和HPC领域都大有可为。MLIR官网还有很多很好的文档和教程,有缘再见吧,我只是想水一个矩阵乘法代码生成器。。。。
如何使用MLIR生成一个单线程高性能矩阵乘法
文章链接:https://arxiv.org/abs/2003.00532
作者是Uday,PLUTO作者
文章以使用MLIR生成高性能矩阵乘法为例,讲述了MLIR生成的高性能程序和手写代码有一定竞争力。
作者认为,通过将程序在IR级别自动分析、自动应用一些变换可以避免手写高性能代码。
这篇文章的内容是面向编译器,使用MLIR应用手写库中使用到的HPC技术。
环境介绍
单核理论峰值75.2GFLOPS(超频至4.7GHz)的Intel Core i7-8700K,私有L1dcache 32KiB,私有L2 cache 256KiB,共享L3 cache 12MiB。
baseline
2088x2048x2048 的dgemm
| 实现方式 | 性能(GFLOPS) |
|---|---|
| 三重循环clang -O3 | 0.47 |
| 三重循环gcc -O3 | 4.53 |
| 多面体编译技术PLUTO | 19.32 |
| blis | 63.29 |
| openblas | 67.49 |
| mkl | 67.70 |
使用MLIR优化GEMM
作者写这篇文章的时候还没有可生成MLIR的前端高级语言,所以选择了直接写MLIR,用mlir-cpu-runner工具jit 编译然后运行。在这个过程中优化后的MLIR会被lower到LLVM IR,然后生成目标代码。下图是MLIR形式的三重循环GEMM代码(???不是2088吗,怎么到这里成2048了):

代码里使用了两种方言Affine和linalg,Op是干啥的见名知意。MLIR里的memref是张量数据在内存中的表示。根据其数据布局,它可能指向底层缓冲区的一个潜在的非连续的子区域。代码片段里的所有memref都是行主序的,map格式为((d0, d1) -> (d0, d1))。memref<2048x2048xf64>代表这是一个数据类型是fp64,shape是2048x2048的张量。仿射layout映射,是指将逻辑坐标映射到物理内存空间的方式。
MLIR可以方便的自定义Op,下面这行代码自定义了一个矩阵乘法Op
1 | hop.matmul %A, %B, %C {some_attr = 96, another_attr = 4} |
作者定义了一个-hopt pass,将hop.matmul扩展成三重循环的IR。性能0.558GFLOPS。
接着作者用多面体调度的形式描述了gotoblas/blis中经典的分块算法:
1 | (i, j, k) -> (j/NC, k/KC, i/MC, j/NR, i/MR, k mod KC, j mod NR, i mod MR) |
上述调度的最里面两重循环会被展开成MRxNR的循环体。MR,NR,KC,MC,NC是根据寄存器数量和各级cache大小选取的。
想在MLIR中实现上述tile算法,有两种方式,一种是在MLIR中可以通过调用mlir::tile pass来实现对循环的tile,然后使用mlir::interchangeLoops pass来交换循环顺序,另一种是基于特定领域和调度,通过实现一个高级多面体(HOP)方法来实现。在这里作者使用了后面这个方法,原因是MLIR现有的仿射分析机制不够完善,没有做必要的简化,有可能生成冗余的代码。HOP方法依赖于ISL外部库(一个多面体编译工具)。作者将tile调度表达为MLIR的仿射,使用ISL进行代码生成,然后将ISL AST翻译回MLIR,hop.matmul Op需要增加分块参数的属性(由于测试规模不大,作者这里忽略了L3cache的分块参数NC)。
1 | hop.matmul %A, %B, %C { M_C = 64 : i32, K_C = 256 : i32, M_R = 4 : i32, N_R = 8 : i32} |
tile方式通过仿射调度的形式指定:
1 | // Scheule 将矩阵乘原始的三个维度映射到了tile后的7个维度 |
作者为了只评估tile后对cache访问的优化,所以暂时忽略了寄存器级的分块
1 | hop.matmul %A, %B, %C { |
生成的可视化MLIR如下: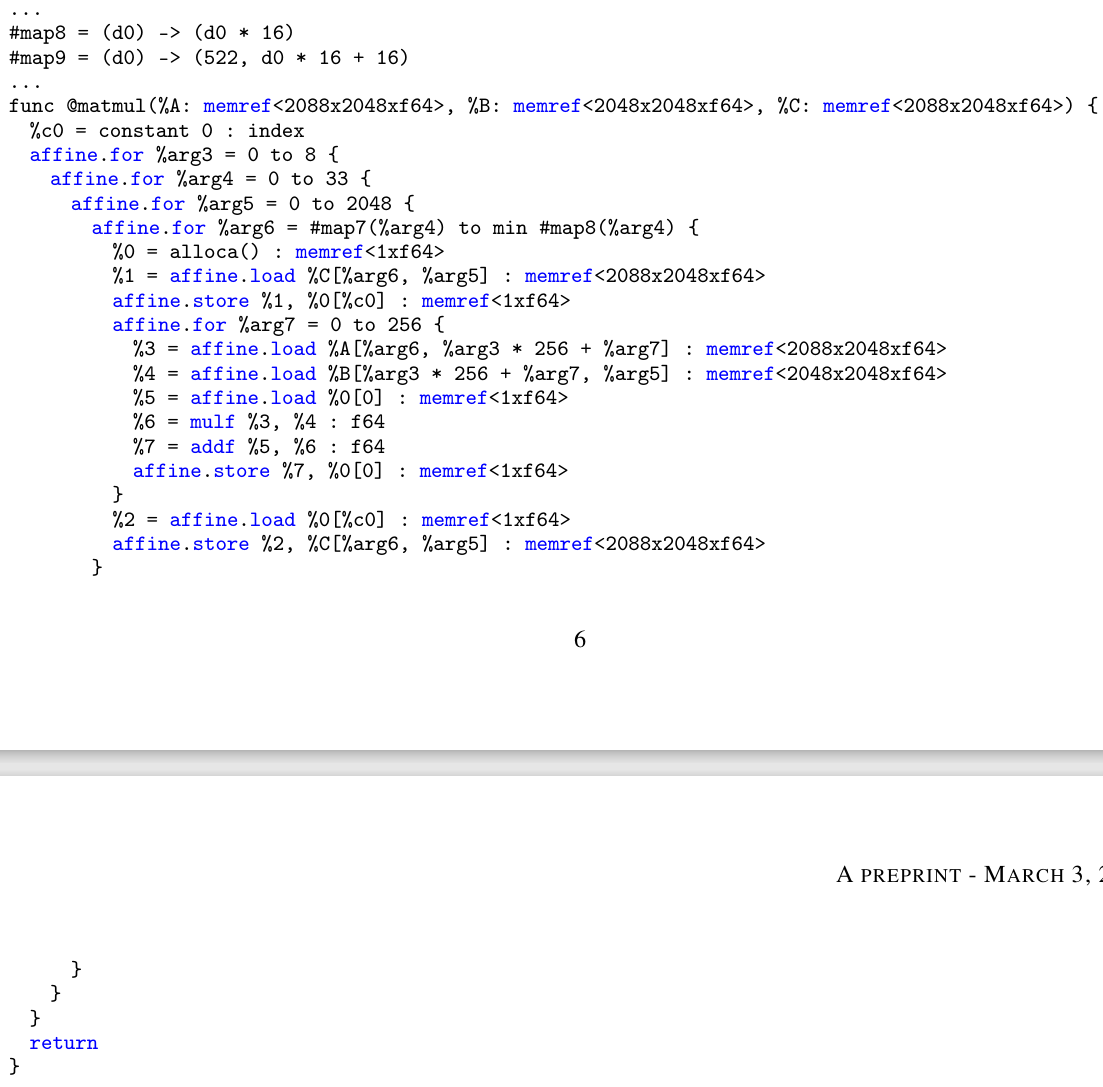
性能只有1.6012GFLOPS。
MLIR中提供-affine-data-copy-generate pass和mlir::affineDataCopyGenerate工具,自动生成将张量显式copy/pack的代码,可以直接用。作者这里选择新增使用mlir::affineDataCopyGenerate工具的pass -hopt-copy,后续还有循环展开,标量代替,向量化步骤,通过-hopt*系列选项来启用pass,这些pass好像都是作者另写的?最终在下面这条命令下:
1 | mlir-opt -hopt -hopt-vect -hopt-copy -hopt-unroll -hopt-scalrep -convert-linalg-to-loops -lower-affine -convert-std-to-llvm dgemm.mlir | mlir-cpu-runner-O3 -e main -reps=5 -entry-point-result=void -shared-libs=lib/libmlir_runner_utils.so |
生成了最终版的MLIR(太长不贴),并达到了49.8336 GFLOPS的性能。调优分块参数之后,性能可达61.939GFLOPS。通过-hopt-blis pass将最里面三重循环替换成blis的手写6x8 kernel后,性能也只有61.421GFLOPS。
总之,有了MLIR之后,手写的各种优化技术都可以变成在IR上操作的一些pass,pass是可以重用的。pass写好之后,对于矩阵乘法来说,只需要给op传不同参数即可生成有上述所有优化技术的代码,例如下面这个可以直接生成高性能sgemm,128.89GFLOPS,最快的MKL也才130.92GFLOPS。
1 | hop.matmul %A, %B, %C { |