[论文学习]使用Exo生成Arm上的高性能microkernel
简介
Tackling the Matrix Multiplication Micro-kernel Generation with EXO,https://arxiv.org/pdf/2310.17408 不知道发在什么级别的会或者期刊,
但是作者列表里有mit和ucb的人,质量应该没问题。
论文作者使用EXO写了一个Arm neon矩阵乘micro kernel代码生成器。https://github.com/adcastel/EXO_ukr_generator
因为是生成的,所以可以方便的尝试不同size的kernel。
文章包含以下内容:
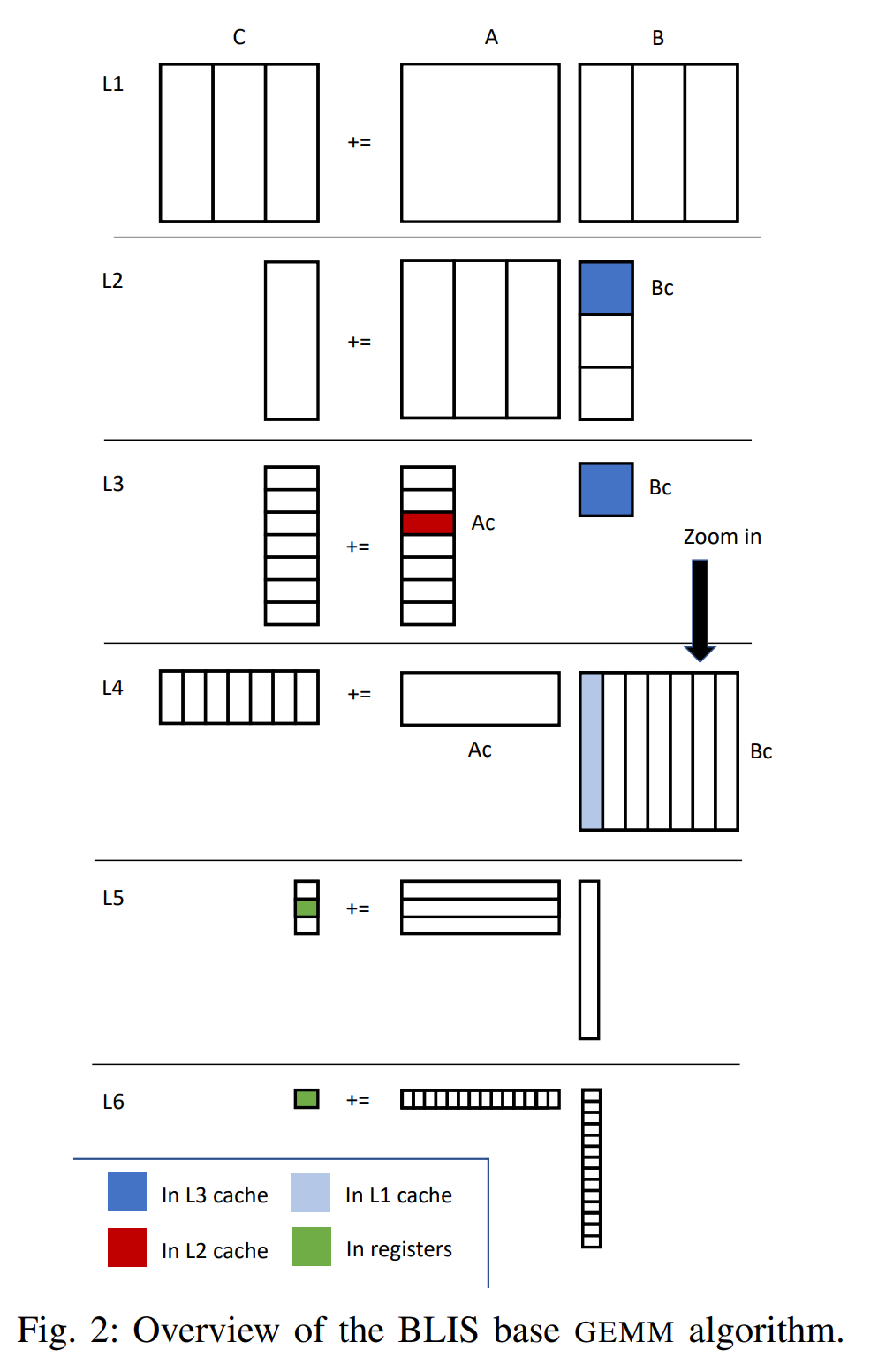
- 单线程 BLIS gemm实现算法
- 介绍Exo语言/编译器
- 详细介绍如何使用Exo生成arm neon高性能micro kernel
- 展示优越性
BLIS gemm
老生常谈的分块packing,macrokernel,microkernel,由于手写kernel太费劲了,所以blis给每个平台只写了一个kernel。
EXO介绍
和大多数编译和调优框架(halid,tvm)类似,给Exo一个操作定义,用户这个操作上,
使用Exo提供的调度原语手动应用一系列优化手段(tiling,vectorize),
不同的是Exo没有和llvm或者特定硬件绑定在一起,具体生成什么平台的代码,需要用户以输入的形式指定。Exo最终生成使用intrinsic的C代码。
作者在这一部分还顺便批判了一下TVM,强调了直接生成C代码的好处(TVM也可以生成C代码,不过好像只能生成调库的那种C代码):1. 不需要什么运行时依赖,2. 可以轻松的以源代码的形式集成到现有库里;
还强调了搜索参数的不必要性,并举了很多例子来辅助论证AutoTVM这种在用户定义模板的基础上搜索参数的方法会造成极大的浪费。
如何使用Exo生成arm neon高性能micro kernel
通过@proc注解标注一个函数是可调度的,然后使用Exo提供的调度函数来手动显式应用一些优化和约束,比如设定分块大小(8x12),
切分循环(8x12->(2x4)x(3x4))等,然后产生调度后的Exo代码,最后根据该代码搭配输入(体系结构特定的intrinsic函数)生成C代码
Exo定义的原始未做优化和调度的gemm micro kernel
作者在这里假设alpha和beta都是1。。。。代码我直接复制的(忽略缩进问题),这里默认C矩阵列主序,A矩阵列主序,B矩阵行主序,保证连续访问
1 | 1 @proc |
设定mr和nr的值为8x12
这里USER CODE是自己手写的,下面的RESULTING EXO GENERATED CODE据说是生成的中间的Exo的表示。
1 | 1 # USER CODE |
按向量长度分割循环
m维分成2x4,n维分成3x4,Exo可以自动生成tile后的ABC矩阵的寻址表达式。
1 | 1 # USER CODE |
目前为止还没有利用寄存器和向量化
将8x12的C矩阵绑定到向量寄存器并使用向量化load/store
据作者说,这一步是最复杂的步骤之一,Exo的写法太自由了。
1 | 1 # USER CODE |
将A,B操作数绑定到向量寄存器并使用向量化load
USER CODE用到的X应该是因为AB操作类似,作者不想在论文里写两遍,所以用的X,实际代码里应该是A和B。
1 | 1 # USER CODE |
交换循环顺序,使用fmla指令完成乘加操作
交换it和jtt循环,循环变为jt->it->jtt->itt->标量乘加,然后将itt->标量乘加替换为向量乘加fmla,最终循环变为jt->it->jtt->fmla
1 | 1 # USER CODE |
k维度循环展开
1 | 1 # USER CODE |
到此结束,没考虑逻辑寄存器的数量,而且生成的C代码是intrinsic,作者不放心,用编译器生成汇编文件检查了一下,
发现和blis手写的差不多(作者说的)。
边缘情况(edge case)
GEMMshape比较奇怪时,比如12554x64x147,分块后,不做padding的话,不是所有的块都能用8x12的kernel,在这个时候,
kernel生成器的作用就体现出来了,只需要改一下MRNR的参数就可以生成和8x12用到相同调度的处理边缘情况的kernel,
虽然同样没考虑可用的逻辑寄存器的数量,但是有tile,向量化,循环展开。作者提到有时候不需要pack,比如size特别小,不需要切分,
需要改一改kernel调度(USER CODE)。
然后讲了一下可移植性和数据类型的切换,只需要替换相应的intrinsic。
性能评估
solo mode
直接单跑5s的kernel,算gflops,图示Exo生成的跟blis的比具有一定优势,8x12情况下据说是因为手写的kernel需要考虑边缘情况,引入了开销。
方阵
对比了blis和把kernel集成进blis还有上层算法的性能,性能有高有低
矩形阵(异形矩阵)
也是有高有低